
З самого початку захопленням фотографуванням (перша камера — 2006 рік) у мене почав накопичуватись великий архів фото-відео бо я прагнув зберегти усі фото, незалежно від того, використані вони якось чи ні.
Професійні фотографи одразу видаляють невдалі кадри, але мені було шкода це робити.
В 2011 році я з jpeg перейшов на RAW і ситуація з вільним місцем лише погіршилась.
Накращим (на мою думку) способом бекапу в «хмари» є спеціалізовані сервіси типу Amazon S3, Amazon Glacier та їх аналоги від Google та Microsoft. Існують програми (Arq, Duplicity і т.п.), які уміють працювати з цими сервісами та робити інкрементальні бекапи. Але подібне більше підходить для компаній та професіоналів, бізнес яких залежить від надійного зберігання результатів їх роботи. Для мене фотографування це хоббі а програмування це робота тому я пішов іншим шляхом.
Box
Навесні 2012 року компанія Box вирішила конкурувати з Dropbox в сегменті домашнього використання, тому почала збільшувати безкоштовні акаунти до 50Гб якщо залогінитись з Box for Android. Я не зміг пройти повз тому зареєстрував кілька десятків акаунтів (про запас 🙂 Оригінальна ідея була зберігати туди музику, але це виявилось не дуже практичним: у мене є дурна звичка час від часу міняти теґи тому треба було перезаливати Lossless треки.
Згодом у мене зʼявилася ідея зберігати туди усі свої фото-відео, які зазвичай дуже рідко змінюються (RAW файли — ніколи бо Lightroom пише зміни в xmp). Процес завантаження був простий — акаунт монтувався по WebDav і за допомогою Fork Lift файли синхронізувалися. Зазичай це відбувалося ночами і нерідко зʼявлялася помилка, яка зупиняла процес до ранку.
На той момент мій основний архів займав приблизно 300Гб. Швидкість інтернету «вгору» була 512 чи 768 Кб/с. Питання: як швидко мені вдалося завантажити 300Гб в таких умовах? Приблизно півроку, з травня по жовтень 🙂
В цьому мені дуже допомогла відмова від WebDav і використання Box API власним скриптом. Помилки завантаження звісно траплялися, але в цьому випадку скрипт просто переходив до наступного файлу. Тоді ж зʼявилася ідея порівнювати локальні та віддалені файли за вмістом а не розміром або датою модифікаці. Box API в цьому питанні дуже зручний — для кожного завантаженого файлу він підраховує SHA1 хеш.
Як же мені вдалося помістити 300Гб на 50Гб акаунт? Я завантажив їх на кілька акаунтів, приблизно по 40Гб на кожен. Оскільки я зберігаю фото в папки з поточною датою в назві (2016_08_21) то було не складно кожному з акаунтів прописати діапазон дат (прямо в тексті скрипта, поруч з API ключами 🙂
Dropbox
Наступним етапом була акція Space Race від Dropbox восени 2012 року. Тоді студенти могли ввести свою студентську поштову скриньку та прокачати свої Dropbox акаунти на 25 Гб на 2 роки. Де ж взяти стільки поштових скриньок в студентському домені? Дякуючи Сумському університету та їх сервісу з відкритою реєстрацією live.sumdu.edu.ua від Microsoft це виявилось не дуже складним завданням. Sumy State University піднявся досить високо в тому рейтингу (здається потрапив в десятку).
Постало питання, як перекинути 300Гб з Box на Dropbox. Робити це знову зі свого компʼютера не було жодного бажання. Тому я використав свій сервер на Linode, який качав файли з однієї «хмари» та заливав їх в іншу. Процес зайняв приблизно місяць: багато дрібних файлів (~ 100к) та не дуже оптимальний процес (скрипт дороблювався в процесі). Заодно я почав зберігати інформацію про локальні та віддалені файли в базу даних MySQL, це спростило їх синхронізацію (не треба було щоразу сканувати локальні папки, лише коли у них щось змінилося).
Також Dropbox використовується у мене для синхронізації фотографій з телефону. Вони завантажуються на основний акаунт, на компʼютері завжди працює Dropbox-клієнт, який завантажує їх локально. Спеціальний скрипт потім розкладає їх по папкам з датами (2016_08_21_n1).
Flickr
В травні 2013 року Yahoo вирішив розворушити свій фото-сервіс Flickr, тому безкоштовні акаунти отримали 1Тб (насправді лише 1 000 000 000 000 байтів, для програмістів це важливо). Це крок був схожий на появу Gmail з 1Гб в 2004 році. Але у Flickr були і обмеження — можна завантажувати лише фото (jpg, png, gif) до 200Мб та відео до 1Гб (при цьому програвалося лише перші 3 хвилини). Першим кроком було завантажити усі формати, які хоч якось підтримувались.
Основна проблема виникла з RAW (nef, cr2 і т.п.) — потрібно було конвертувати їх в jpeg перед завантаженням, втрачаючи можливість повноцінно редагувати пізніше. Але я знайшов технологію (формат?) RarJpeg коли з RAW файлу генерувався jpeg повного розміру, RAW файл запаковувався в rar архів і дописувався в кінець файлу jpeg. Завдяки особливостям форматів jpeg та rar результат був одночасно коректною картинкою та архівом. Але оскільки на той час створення архіву відбувалося на Raspberry Pi з ARM процесором та Linuxʼом то використання rar було складним (неможливим?). Також не дуже хотілося звʼязуватися з комерційною програмою. Зате 7-zip чудово працював (і досі працює).
Flickr API виявився дуже складною та нестабільною штукою. Можна було без проблем створити альбом і почати завантажувати в нього файли, але якщо через 10-20 хвилин запросити список усіх альбомів то його там могло не виявитися. Мій початковий скрипт в такому разі створював новий альбом і починав завантажувати файли знову. В результаті виникали дивні ситуації з дублями і т.п. Лише після кількох років боротьби та розробки мій скрипт став настільки розумним, що навчився уникати більшості проблем з Flickr API. Хоча дивні ситуації все одно зрідка трапляються. Досвід роботи з API, який я отримав в процесі — безцінний.
Саме з появою практично безлімітного Flickr у мене виникла ідея бекапити не лише основний архів (на той час вже десь 350Гб), але й невикористані RAW файли (на той момент — 600Гб). На Dropboxʼі вже не було достатньо місця, зате акція на Box ще тривала (правда лише для телефонів LG, яким є мій Nexus 4) і кількість моїх акаунтів зросло до 80 бо я наївно сподівався, що цього має вистачити на дуже довго :). Кількість акаунтів на Flickr теж не залишилась сталою 🙂
Onedrive
В лютому 2015 року Microsoft почав дуже активно просувати свій OneDrive і запустив акції з Dropbox та Bing: 100Гб на 1 рік та ще 100Гб на 2 роки. Як вже не складно здогадатися, одним акаунтом я не обмежився. Приблизно в цей час вони почали запускати нове OneDrive API, робота з яким була досить легкою (на відміну від старого SkyDrive API). Більше особливо про OneDrive мені сказати нічого — працює добре, проблем мінімум (великі файли доводиться завантажувати по 60Мб), але основне місце закінчиться в лютому 2017.
Mega
Сервіс від Kim Dotcom. З одного боку захищений та надає 50Гб без жодних акцій, з іншого — API складне, криптографія занадто важка для PHP тому доводиться використовувати консольні програми з пакету megatools. Зараз сервіс вже має інших власників (якісь китайські інвестори) тому подальша доля його невідома. Але я його поки підтримую бо особливих проблем він не викликає.
Amazon Drive
В травні 2015 року Amazon вирішив позмагатися з Dropbox, Onedrive, Google Drive і т.п. тому оновив свій Cloud Drive. У ньому зʼявилося 2 нові тарифні плани: Unlimited Everything за $5/місяць та Unlimited Photos за $1/місяць.
Мене зацікавив план Unlimited Photos тому я вирішив перевірити, які формати вважаються фотографіями. Виявилось, що усі, які я перевіряв, навіть nef, cr2, dng, tif, psd і т.п. Це став перший сервіс, за який я почав платити (правда не довго бо через 4 чи 5 місяців мені прийшов код для Unlimited Everything на рік).
Amazon Cloud Drive API виявилося дуже нестабільним. Я розумію, що сервіс привабливий за ціною, і що знайшлося купа бажаючих ним скористатися, але все ж Amazon міг щось придумати. Довелося дороблювати свій скрипт, щоб він нормально реагував на часту та тривалу недоступність сервісу. Зараз ситуація наче виправилась. Незважаючи на Unlimited Everything я бекаплю лише фото бо восени планую повернутися на Unlimited Photos.
Google Drive
Навесні 2016 Google почав акцію серед користувачів Local Guides, які залишали огляди щодо місць, де вони побували, відповідали на питання та завантажували фотографії. Якщо набрати 200 очків та досягти 4-го рівня то надавався 1Тб на 2 роки. Я не одразу почав писати відгуки та відповідати на питання, але, на щастя, встиг це зробити для кількох акаунтів, поки бонус не зменшили до 100Гб в червні. Оскільки я поки не вирішив, чи буду продовжувати використовувати Google Drive для бекапу фото-відео через 2 роки тому створив та «прокачав» додаткові акаунти на власному домені (а не основний).
Google це Google тому особливих проблем з API не було. Єдина суттєва особливість — папки та файли віртуальні, тому немає перевірки на унікальність імен (так само, як і у Flickr). Усі інші сервіси скажуть, що файл вже існує, або просто перезапишуть його. Тому довелося дописувати скрипт щоб випадково не створювати дублікати.
Додаткова зручність — я розшарив папки з додаткових акаунтів на основний тому маю зручний доступ в Google Drive на телефоні до усіх файлів.
Інші сервіси
Bitcasa восени 2015 року роздавала 25 Гб для розробників, щоб вони могли потестувати їх новий CloudFS сервіс. Я вирішив замінити ним Dropbox, який на той час вже забрав бонусне місце. Використавши свою звичку тактику я зміг розмістити там основний архів (500Гб). Але через деякий час (кілька місяців) мені написали з пропозицією обговорити співпрацю (почати платити). Я проігнорував листи а через півроку вони оголосили про згортання сервісу. Ну не дуже і хотілося 🙂
Mail.ru (прохання не кидати в мене гнилі помідори) запустив акцію для своєї «хмари» в кінці 2013 року. Я не збирався ним користуватися, але через жагу до дослідження нових сервісів все ж прокачав 2 акаунти до 1Тб.
В лютому 2016, коли Microsoft забрав перші 100Гб, я все ж вирішив надати Mail.ru шанс. Але завантажувати «голі» файли було дуже ризиковано. В хід пішло PGP шифрування та приховування імен файлів. Поки що це все живе, але думаю не на довго 🙂
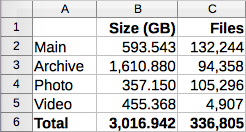
Результат
У мене є система, яка забекапила майже 3Тб фото-відео-аудіо (мої та Олександри) паралельно на 7 сервісів (невикористані RAW та відео — лише на 6) та продовжує це робити.
Скрипт на Synology NAS завантажує файли на Box (так історично склалося), далі він запускає скрипт на моєму сервері на Linode, який переносить файли на Google Drive а потім і на інші «хмари» (Flickr, Amazon, Onedrive, Mega, Mail.ru). Все це працює в автоматичному режимі але процес я запускаю вручну коли фотографії вже розібрані та оброблені, щоб невикористані RAW не потрапили в основний архів.
Надійсність кожного з сервісів викликає питання (особливо через їх безкоштовність), але усі одразу вони навряд зникнуть. Також у мене є локальна копія, правда частину невикористаних RAW довелося видалити. Але колись я завантажу їх назад 🙂
Майбутнє
OneDrive забере бонусне місце за півроку, Google — за півтора. Я сподіваюсь, що файли просто стануть read-only. Місце на Box з часом закінчиться (нових акцій давно не було, існуючі акаунти неправильно рахують вільне місце тому деякі пусті вже переповнені). Думаю мають зʼявитися нові сервіси (з мого досвіду — мінімум раз на рік). Система спроектована з розрахунку на легку інтерграцію нових сервісів, зазвичай це справа кількох днів. З іншого боку вимкнути якийсь сервіс дуже просто, тому можливо з часом залишаться лише кілька найзручніших (для прикладу, Amazon та Flickr). Життя покаже 🙂
Поради
Бекапити усе, що може мати хоч якусь цінність. Я розумію, що мало хто буде морочитись так, як це роблю я. Але використати Flickr або Amazon Drive можна навіть без особливих навичок з програмування. Нічого так не тішить душу, коли знаєш, що усі файли є ще десь і локальний комп’ютер/NAS не містить нічого важливого в 1 екземплярі.